Note: Article has been updated since original submission April 9, 2015 for a college assignment.
Summary:
The following report covers what root cause analysis is and how it can be applied to software engineering. Root cause analysis or RCA identifies the root cause of a problem, which by fixing the root cause, all defects and associated defects will cease to occur. It can be used as a supplementary process to identify and fix errors that may occur. Software development cycle can be improved by using RCA, since it may increase the efficiency of fixing errors in a system. In other contexts, RCA is used as quality management and failure analysis tools to understand errors, which if applied to software development, it may yield positive results.
Key Things Learned
- Root cause analysis has a series of steps that are to be followed, almost like the scientific method.
- Root cause analysis can be used as a tool to fix errors in software.
- Asking “why” continuously about a defect can lead to the root cause.
- Fixing errors in software development may be made easier by using root cause analysis.
- Root cause analysis is a quality management tool and failure analysis tool for multiple contexts and should be further applied in software development.
Software, Tools, Apps, Used and Evaluated
The most popular or general tools for root cause analysis are cause mappings that show relationships between defects, possible causes, and their associated factors. They are used to help identify which cause is the ultimate cause (root cause) of a defect in a plain view (Otegui 188). One example of this is fishbone diagrams. They break down causes into branches and associate attributes or factors to each cause. This cause-effect diagram is read from right to left as in the Japanese language since its creator was Kaoru Ishikawa (“Root Cause Analysis”). Figure 1 is a computer-based fish bone example. The idea is that a server has crashed and that the ends of the bone are possible causes such as the method, men (workers), the workers, technology, and policy. Along each bone are associated factors or more detailed descriptions of each major bone. By representing the data from a root cause analysis in this way, it may be easier to question “why” at each part and understand which bone is the ultimate root cause.
Figure 1. Server Crash Fish Bone Diagram.
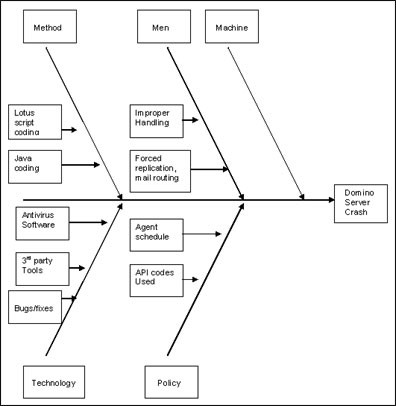
Source: Dhandapani, Dhanasekar. Fishbone Diagram Part 3. Digital image. IBM DeveloperWorks. IBM, 21 June 2004. Web.
Another possible representation of root cause analysis is cause-effect mapping which is more of a plain text view of the analysis known as the five “why” approach by Sakichi Toyoda (“Root Cause Analysis”). Note that the diagram is also read from right to left. Instead of breaking the data collected from the defect into a fish structure, like in a fishbone diagram, a cause-effect mapping is more like a chain of events. Figure 2 is a generic outline of a five why approach. The process begins with a defect(s) and then is questioned with a why which leads to another why and so on. This process is done repeatedly until one arrives at the conclusion that they have the final cause. The diagram also allows for even more extensions of why it can technically go on longer than five why questionings.
Figure 2. Five why approach.
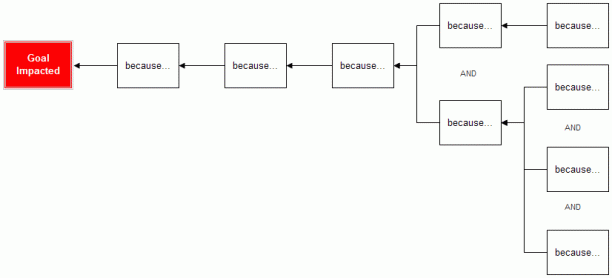
Source: 5 Whys on a Cause Map. Digital image. ThinkReliability. ThinkReliability, 2011. Web. <http://www.thinkreliability.com/Root-Cause-Analysis-CM-Basics.aspx>.
Either diagram can be used in root cause analysis. They are visual aids that have helped develop the root cause analysis process into what it is. Root cause analysis can help identify and clarify what is going on in a context.
Findings
Introduction
Root cause analysis is the process of finding the underlying cause of a defect. This is known as the root cause. Ideally, upon finding the root cause, it will be simpler to find and fix a solution for the root cause. Therefore, it eliminates the root cause and other defects and factors associated with the original defect. This analysis reduces overexertion on fixing problems, errors, and defects. It may ultimately lead to a more efficient system and mitigate problems.
Originally, root cause analysis (RCA) has origins in Japan, from the creation of the fishbone diagram by Kaoru Ishikawa. These diagrams help understand what are the causes of problems and what are their associated factors (refer to Software, Tools, Apps, Used and Evaluated). Root cause analysis has since gained popularity as a quality management tool for projects and problems. More recent case studies and implications have focused on studying disasters. For example, NASA studied the 1996 explosion of the Challenger spaceship with RCA. Questions such as “Why was there no eject safety procedures?”, “How was the ship able to simultaneously combust?” were from a large debate of what caused the Challenger to explode (Otegui 184). If these questions were efficiently addressed, such as finding the root cause of the problem, then it may have been possible to stop the explosion. RCA is now formally adapted, almost as its own scientific method, to understand problems of a situation and be able to fix those problems. It is applied to many areas, not just software, such as engineering, business, science, etc.
1.2 Process of Root Cause Analysis
The first step with RCA is to identify and define the defect or error of a context. RCA is used for after the fact. The assumption is that a defect must be known in order to truly understand the entire context of the defect. Identifying the error helps associate the context with the outcome. The next step in RCA is to collect data associated with the defect (Otegui 186). By collecting the data of the defect, it will be clearer what other problems or defects are associated with the original defect. It will also help create understanding of the entire context of the defect. The next step is to understand, possibly draw out a possible tree, of events, factors, and defects associated with the original defect. This may create a clear view of what thing causes everything else to happen (refer to Software, Tools, Apps, Used and Evaluated).
Next step is to question which parts are true causes for the defects. A way to do this is to repeatedly question “why” for every event/factor (Shore and Warden). For example, if one were asked why a fuse blew out, one could say that the fuse needed to be changed. Then, that event could be questioned even further. The fact that the fuse needed to be changed is true, but why did it need to be changed. A possible solution is that the circuitry was faulty, and so on. Continuously questioning why will eventually lead to an underlying cause or root cause of a situation. In order to check this possible root cause, it is necessary to check the cause-effect relationship and make sure it applies to the original defect. Continuing on with the fuse example, the fuse circuitry was faulty which needed to be changed, and the fuse blew because of it (Otegui 187). It is necessary to check if the logic is sound to ensure the validity of the defect. After confirming the root cause, a solution should be created to address the root cause. The ultimate result will be that the defect and other associated defects will no longer occur.
Use in Software Engineering
The software development process is not without errors. Even with the best-created requirements, test cases, etc., errors will still happen. As Murphy’s Law states, “if something can go wrong, it will” (Shore and Warden). It is illogical for the entire software development cycle to have no errors. When these errors occur, it is necessary to have a process that addresses these errors and is able to understand them. Root cause analysis can be used in software engineering to fix errors at any part of the software development cycle. It could be during the design stage or even production stage when problems arise. In theory, root cause analysis, in general, is the investigation of an unwanted event and how to fix it (Jenkins). The unwanted event is created from a base of factors and evidence that shows that the root cause is at the top, like a pyramid.
If RCA is used with software engineering, it can be used as a quality management technique to oversee errors with the software process. Ideally, RCA would prevent a repeated defect from happening again. It can also fix, most likely, multiple errors associated with the root cause at one time. This may reduce time spent trying to fix each error at a time, which is important to software development as people want efficient software for low cost and time (Shore and Warden). Another key use is that many problems that occur in a software system are either repeated errors or of a similar nature, which could show a common or root cause. For example, when compiling a program, a null pointer error exception is returned. One can fix that one or few lines of code and the error is fixed. But another error appears again, this time it is also a null pointer exception in another location. This shows some sort of symmetry in a problem that may be solved by conducting root cause analysis. If software developers were to apply RCA to this example, one could study the associated data, diagram the results and then begin questioning. The first question would be why is there a null pointer exception? The answer, there was no test for this scenario. Again, why was there no test for this scenario, and so on. By doing RCA, a better and more informative answer can be found, rather than just saying “there was no testing” (Shore and Warden).
One environment in software development, agile development, optimizes the root cause analysis scheme. Agile development is the idea of completing the software development cycle from start to finish multiple times. Although the software system is not perfect, it is able to be perfected by creating a series of versions of the system (Shore and Warden). The multiple iterations of a system aid the process of RCA. RCA is most useful for analyzing common errors. These common errors are usually very similar in nature and have near identical results. The idea is that during the agile development cycle, one can see problems in a relatively short time frame and in different contexts and constraints (Jenkins). This would improve the data scheme of a problem and showcase that if there are repeated problems, there is likely some root cause to the repeated problems in the software system. RCA is ideal for this type of situation.
Consequences from Using RCA
Root cause analysis provides a better understanding of failures. It will efficiently fix defects and also prevent them from happening. Besides fixing the overlying defects and further preventing the same or similar defects, RCA in software engineering will cause software development teams to cooperate, and to spend less time blaming a part that went bad (Shore and Warden). In turn, this enables to create retrospectives of the situation and may ameliorate the knowledge of all team members of the software system’s context at hand. Also, and most importantly, using root cause analysis can improve the overall software quality of the system. RCA helps create the most efficient system by reducing the most inefficient errors in one blow (figuratively speaking, possible to do RCA multiple times). This is done at a relatively lower cost and time spent because the time spent doing RCA will reduce time and cost for repeating expensive processes such as testing (Jenkins). RCA helps promote efficient and time/cost effective products with practical and good results.
Yet, root cause analysis is not always “good”. Although root cause analysis has been seen in a positive view, it may be possible to over apply root-cause analysis. As said earlier, “what can go wrong, will go wrong”. Root cause analysis increases overhead in the system, that is one will know what, when, where, how something is going to happen. This may require a lot of time and more in-depth understanding of the system, which may not be possible in larger operations (Shore and Warden). Also not everything is RCA applicable. This means that some cases may not need RCA in the sense of having a thorough understanding. Some things are just simple and not complex which RCA may prove to be. RCA can also be proved to be inefficient when trying to fix a non-common problem. Common problems or repeated problems show that they probably share or have very similar root causes. Non-common problems show that it may have been a onetime thing, so RCA is not required in this case (“Root Cause Analysis”). Another issue with RCA, is that there is an assumption that the root cause can be fixed, which is not necessarily true. It could be that software developers do not have the skill to fix the root cause and are unable to get the resources to fix it (Shore and Warden). Even more important is the fact that the root cause could be completely outside of the team’s scope to fix it. Scope as in it is unable to be fixed because it is unable to be controlled. For example, if a rainy day caused a car to slide, one doesn’t blame their tires, they blame the weather. But they cannot control the weather. In terms of software, an example of a limited scope may be that a company requires the use of a certain standard or hardware that cannot be changed no matter what. The software development team will be unable to fix the root cause.
Problems / Questions / Further Work
The following report is generated based on existing research of root cause analysis. Root cause analysis can be applied to multiple contexts, such as engineering, software development, etc. But in terms of RCA being used with every software development cycle, there is not much documentation of root cause analysis as a tool specifically for software engineering. Some agile development teams may already use root cause analysis thinking, but they do not necessarily implement it formally. In the future, more research can be done with using root cause analysis techniques formally as a standard with software engineering. Also there more research could be done on the relationship between software quality and root cause analysis.
Change Control and Updates
Version 1.0 (original) Julie Leong, 04/09/2015
Version 2.0 (updated) Julie Leong, 05/24/2018
References
Jenkins, Nick. “Root Cause Analysis.” A Software Testing Primer:. Software QA Testing Resource Center, 2008. Web. 10 Apr. 2015. <http://sqa.fyicenter.com/Introduction_to_Software_Testing/35_Root_Cause_Analysis.html>.
Otegui, Jose Luis. Failure Analysis : Fundamentals and Applications in Mechanical Components. Cham: Springer International Publishing, 2014. Ebook Library. Web. 06 Apr. 2015.
“Root Cause Analysis.” :: Cause Mapping Basics. ThinkReliability, 1 Jan. 2011. Web. 10 Apr. 2015. <http://www.thinkreliability.com/Root-Cause-Analysis-CM-Basics.aspx>.
Shore, James, and Shane Warden. “The Art of AgileSM.” James Shore: The Art of Agile Development: Root-Cause Analysis. O’reilly Media, Inc., 1 Jan. 2008. Web. 10 Apr. 2015. <http://www.jamesshore.com/Agile-Book/root_cause_analysis.html>.